本文共 19044 字,大约阅读时间需要 63 分钟。
逐步建立深层神经网络
欢迎来到你的第4周作业(第1部分,共2部分)!您之前已经训练了一个两层神经网络(只有一个隐藏层)。本周,你将建立一个深度神经网络,你想要多少层就有多少层!
在这个部分中,您将实现构建深层神经网络所需的所有功能。 在下一个作业中,您将使用这些函数来构建用于图像分类的深层神经网络。 完成这项任务后,您将能够:
- 使用像ReLU这样的非线性单元来改进模型
- 建立一个更深的神经网络(有一个以上的隐藏层)
- 实现一个易于使用的神经网络类
1 -准备软件包
让我们首先导入您在本次任务中需要的所有包。
- numpy:是使用Python进行科学计算的主要软件包。
- matplotlib:是一个用Python绘制图形的库。
- dnn_utils:为此笔记本提供了一些必要的功能。
- 测试用例:提供了一些测试用例来评估你的函数的正确性
- np.random.seed(1):用于保持所有随机函数调用的一致性。这将有助于我们给你的工作评分。请不要换种子。
import numpy as npimport h5pyimport matplotlib.pyplot as pltfrom testCases_v2 import *from dnn_utils_v2 import sigmoid, sigmoid_backward, relu, relu_backward%matplotlib inlineplt.rcParams['figure.figsize'] = (5.0, 4.0) # set default size of plotsplt.rcParams['image.interpolation'] = 'nearest'plt.rcParams['image.cmap'] = 'gray'%load_ext autoreload%autoreload 2np.random.seed(1)
2 -作业大纲
为了构建你的神经网络,你将实现几个“帮助函数”。这些辅助函数将在下一个任务中用于构建两层神经网络和一个L层神经网络。您将实现的每个帮助函数都将有详细的说明,指导您完成必要的步骤。以下是这项作业的大纲,您将:
- 初始化两层神经网络和L层神经网络的参数。
- 实施正向传播模块(下图中用紫色显示)。
- 完成层的前向传播步骤的线性部分(结果在Z[l])。
- 我们给你激活函数(relu/sigmoid)。
- 将前面两个步骤合并成一个新的[LINEAR-> ACTIVATION]向前函数。
- 将[LINEAR-> ACTIVATION]向前函数L-1堆叠一次(对于层1至L-1),并在末尾添加一个 [LINEAR->SIGMOID](对于最 后一层L)。这给了你一个新的L_model_forward函数。
- 计算损失。
- 实现反向传播模块(下图中用红色表示)。
- 完成图层反向传播步骤的线性部分。
- 我们给你激活函数的梯度(relu_backward/sigmoid_backward)
- 将前面两个步骤合并成一个新的[LINEAR->ACTIVATION]向后函数。
- 堆叠 [LINEAR->RELU] 向后函数 L-1次,并在新的L_model_backward函数中向后添加 [LINEAR->SIGMOID]
- 最后更新参数。

请注意,对于每个正向函数,都有一个相应的反向函数。这就是为什么在转发模块的每一步,您都将在缓存中存储一些值。缓存的值对于计算梯度很有用。在反向传播模块中,您将使用缓存来计算梯度。这个作业将向你展示如何执行这些步骤。
3 -初始化参数
您将编写两个帮助函数来初始化模型的参数。第一个函数将用于初始化两层模型的参数。第二个将把这个初始化过程推广到L层。
3.1 - 两层的神经网络(复习上周内容)
练习:创建和初始化两层神经网络的参数。
说明:
- 模型的结构是:线性->ReLU->线性->sigmod函数。
- 对权重矩阵使用随机初始化。使用正确维度 np.random.randn(shape)*0.01。
- 对偏置使用零初始化。使用 np.zeros(shape) 。
# GRADED FUNCTION: initialize_parametersdef initialize_parameters(n_x, n_h, n_y): """ 此函数是为了初始化两层网络参数而使用的函数。 参数: n_x - 输入层节点数量 n_h - 隐藏层节点数量 n_y - 输出层节点数量 返回: parameters - 包含你的参数的python字典: W1 - 权重矩阵,维度为(n_h,n_x) b1 - 偏向量,维度为(n_h,1) W2 - 权重矩阵,维度为(n_y,n_h) b2 - 偏向量,维度为(n_y,1) """ np.random.seed(1) ### START CODE HERE ### (≈ 4 lines of code) W1 = np.random.randn(n_h, n_x) * 0.01 b1 = np.zeros((n_h, 1)) W2 = np.random.randn(n_y, n_h) * 0.01 b2 = np.zeros((n_y, 1)) ### END CODE HERE ### # 使用断言确保我的数据格式是正确的 assert(W1.shape == (n_h, n_x)) assert(b1.shape == (n_h, 1)) assert(W2.shape == (n_y, n_h)) assert(b2.shape == (n_y, 1)) parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2} return parameters 测试:
parameters = initialize_parameters(2,2,1)print("W1 = " + str(parameters["W1"]))print("b1 = " + str(parameters["b1"]))print("W2 = " + str(parameters["W2"]))print("b2 = " + str(parameters["b2"])) 结果:
W1 = [[ 0.01624345 -0.00611756] [-0.00528172 -0.01072969]]b1 = [[0.] [0.]]W2 = [[ 0.00865408 -0.02301539]]b2 = [[0.]]
3.2 -L层的神经网络
更深的L层神经网络的初始化更加复杂,因为有更多的权重矩阵和偏置向量。完成initialize_parameters_deep时,您应该确保每个层之间的尺寸匹配。回想一下,n[l]是层l中的单位数。假设X(输入数据)的维度为(12288,209)(有m=209个例子):

请记住,当我们用python计算+WX+b时,它会实现广播机制。例如,如果:

然后WX+b将会是:
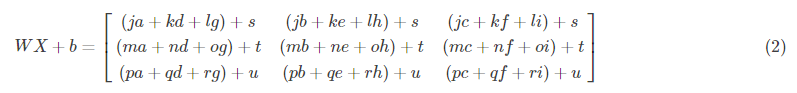

练习: 实现一个L层神经网络的初始化。
说明:
- 模型的结构是 [LINEAR -> RELU] ×× (L-1) -> LINEAR -> SIGMOID. I.e.。它具有使用ReLU激活函数的 L-1层,随后是具有sigmoid激活函数的输出层。
- 对权重矩阵使用随机初始化,使用 np.random.rand(shape) * 0.01。
- 对偏置使用零初始化,使用 np.zeros(shape)。
- 我们将把n[l],不同层中的单位数,存储在一个可变的 layer_dims 中。例如,上周“平面数据分类模型”的 layer_dims 应该是[2,4,1]:有两个输入,一个隐藏层有4个隐藏单元,一个输出层有1个输出单元。因此意味着W1的维度是(4,2),b1是(4,1),W2是(1,4),b2是(1,1)。现在你将把它推广到L层!
- 以下是 L=1(单层神经网络)的实现。它应该会激励你实现一般情况(L层神经网络)。
if L == 1: parameters["W" + str(L)] = np.random.randn(layer_dims[1], layer_dims[0]) * 0.01 parameters["b" + str(L)] = np.zeros((layer_dims[1], 1))
代码部分:
# GRADED FUNCTION: initialize_parameters_deepdef initialize_parameters_deep(layer_dims): """ 此函数是为了初始化多层网络参数而使用的函数。 参数: layers_dims - 包含我们网络中每个图层的节点数量的列表 返回: parameters - 包含参数“W1”,“b1”,...,“WL”,“bL”的字典: W1 - 权重矩阵,维度为(layers_dims [1],layers_dims [l-1]) bl - 偏向量,维度为(layers_dims [1],1) """ np.random.seed(3) parameters = {} L = len(layer_dims) # 网络层中的层数 for l in range(1, L): ### START CODE HERE ### (≈ 2 lines of code) # layer_dims = [5,4,3] # n0=5 n1=4 n2=3 parameters['W' + str(l)] = np.random.randn(layer_dims[l], layer_dims[l-1]) * 0.01 parameters['b' + str(l)] = np.zeros((layer_dims[l], 1)) ### END CODE HERE ### # 确保我要的数据的格式是正确的 assert(parameters['W' + str(l)].shape == (layer_dims[l], layer_dims[l-1])) assert(parameters['b' + str(l)].shape == (layer_dims[l], 1)) return parameters 测试:
parameters = initialize_parameters_deep([5,4,3])print("W1 = " + str(parameters["W1"]))print("b1 = " + str(parameters["b1"]))print("W2 = " + str(parameters["W2"]))print("b2 = " + str(parameters["b2"])) 结果:
W1 = [[ 0.01788628 0.0043651 0.00096497 -0.01863493 -0.00277388] [-0.00354759 -0.00082741 -0.00627001 -0.00043818 -0.00477218] [-0.01313865 0.00884622 0.00881318 0.01709573 0.00050034] [-0.00404677 -0.0054536 -0.01546477 0.00982367 -0.01101068]]b1 = [[0.] [0.] [0.] [0.]]W2 = [[-0.01185047 -0.0020565 0.01486148 0.00236716] [-0.01023785 -0.00712993 0.00625245 -0.00160513] [-0.00768836 -0.00230031 0.00745056 0.01976111]]b2 = [[0.] [0.] [0.]]
4 -前向传播模块
4.1 -线性向前
现在您已经初始化了参数,您将执行正向传播模块。您将从实现一些基本功能开始,这些功能将在以后实现模型时使用。您将按此顺序完成三项功能:
- LINEAR
- LINEAR -> ACTIVATION 其中 ACTIVATION 将为 ReLU 或 Sigmoid.
- [LINEAR -> RELU] × (L-1) -> LINEAR -> SIGMOID (整个模型)
线性正向模块(在所有示例中矢量化)计算以下等式:

练习: 建立正向传播的线性部分。(与上周作业相同)
提醒:该单位的数学表示为 公式(4),您也可能会发现 np.dot() 很有用。如果您的尺寸不匹配,打印 W.shape 可能会有所帮助。
# GRADED FUNCTION: linear_forwarddef linear_forward(A, W, b): """ 实现前向传播的线性部分。 参数: A - 来自上一层(或输入数据)的激活,维度为(上一层的节点数量,示例的数量) W - 权重矩阵,numpy数组,维度为(当前图层的节点数量,前一图层的节点数量) b - 偏向量,numpy向量,维度为(当前图层节点数量,1) 返回: Z - 激活功能的输入,也称为预激活参数 cache - 一个包含“A”,“W”和“b”的字典,存储这些变量以有效地计算后向传递 """ ### START CODE HERE ### (≈ 1 line of code) Z = np.dot(W,A) + b ### END CODE HERE ### assert(Z.shape == (W.shape[0], A.shape[1])) cache = (A, W, b) return Z, cache
测试:
A, W, b = linear_forward_test_case()Z, linear_cache = linear_forward(A, W, b)print("Z = " + str(Z)) 结果:
Z = [[ 3.26295337 -1.23429987]
4.2 -前向传播的线性激活部分
为了更方便,我们将把两个功能(线性和激活)分组为一个功能(LINEAR-> ACTIVATION)。 因此,我们将实现一个执行LINEAR前进步骤,然后执行ACTIVATION前进步骤的功能。
练习: 实现 LINEAR->ACTIVATION 的正向传播。
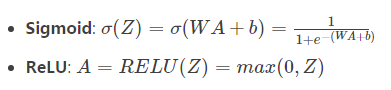 (非线性部分/激活部分)
(非线性部分/激活部分)
我们为了实现LINEAR->ACTIVATION这个步骤, 使用的公式是:![]() ,其中,函数g会是sigmoid() 或者是 relu(),当然,sigmoid()只在输出层使用,现在我们正式构建前向线性激活部分。
,其中,函数g会是sigmoid() 或者是 relu(),当然,sigmoid()只在输出层使用,现在我们正式构建前向线性激活部分。
为了更方便,您将把两个函数(线性和激活)组合成一个函数(线性->激活)。因此,您将实现一个函数,该函数先执行线性前进步骤,然后执行激活前进步骤。
# GRADED FUNCTION: linear_activation_forwarddef linear_activation_forward(A_prev, W, b, activation): """ 实现LINEAR-> ACTIVATION 这一层的前向传播 参数: A_prev - 来自上一层(或输入层)的激活,维度为(上一层的节点数量,示例数) W - 权重矩阵,numpy数组,维度为(当前层的节点数量,前一层的大小) b - 偏向量,numpy阵列,维度为(当前层的节点数量,1) activation - 选择在此层中使用的激活函数名,字符串类型,【"sigmoid" | "relu"】 返回: A - 激活函数的输出,也称为激活后的值 cache - 一个包含“linear_cache”和“activation_cache”的字典,我们需要存储它以有效地计算后向传递 """ if activation == "sigmoid": # Inputs: "A_prev, W, b". Outputs: "A, activation_cache". ### START CODE HERE ### (≈ 2 lines of code) Z, linear_cache = linear_forward(A_prev, W, b) A, activation_cache = sigmoid(Z) ### END CODE HERE ### elif activation == "relu": # Inputs: "A_prev, W, b". Outputs: "A, activation_cache". ### START CODE HERE ### (≈ 2 lines of code) Z, linear_cache = linear_forward(A_prev, W, b) A, activation_cache = relu(Z) ### END CODE HERE ### assert (A.shape == (W.shape[0], A_prev.shape[1])) cache = (linear_cache, activation_cache) return A, cache
测试:
A_prev, W, b = linear_activation_forward_test_case()A, linear_activation_cache = linear_activation_forward(A_prev, W, b, activation = "sigmoid")print("With sigmoid: A = " + str(A))A, linear_activation_cache = linear_activation_forward(A_prev, W, b, activation = "relu")print("With ReLU: A = " + str(A)) 结果:
With sigmoid: A = [[0.96890023 0.11013289]]With ReLU: A = [[3.43896131 0. ]]
注意:在深度学习中,“[LINEAR->ACTIVATION]”计算被视为神经网络中的一个单层,而不是两层。
4.3-L层模型
为了在实现L层神经网络时更加方便,您将需要一个函数,它将前一个函数 (linear_activation_forward with RELU) 复制L次,然后用一个 linear_activation_forward with SIGMOID 复制1次。

练习:实现上述模型的正向传播。
说明:在下面的代码中,AL表示![]() . (也可称作 Yhat,数学表示为 Y^.)
. (也可称作 Yhat,数学表示为 Y^.)
- 使用您之前编写的函数
- 使用for循环复制 [LINEAR->RELU] (L-1)次
- 不要忘记跟踪“缓存”列表中的缓存。要向列表中添加新值c,可以使用list.append(c)
# GRADED FUNCTION: L_model_forwarddef L_model_forward(X, parameters): """ 实现[LINEAR-> RELU] *(L-1) - > LINEAR-> SIGMOID计算前向传播,也就是多层网络的前向传播,为后面每一层都执行LINEAR和ACTIVATION 参数: X - 数据,numpy数组,维度为(输入节点数量,示例数) parameters - initialize_parameters_deep()的输出 返回: AL - 最后的激活值 caches - 包含以下内容的缓存列表: linear_relu_forward()的每个cache(有L-1个,索引为从0到L-2) linear_sigmoid_forward()的cache(只有一个,索引为L-1) """ caches = [] A = X L = len(parameters) // 2 # 神经网络的层数=参数个数/2 print("keys in parameters: ", parameters.keys()) # Implement [LINEAR -> RELU]*(L-1). Add "cache" to the "caches" list. for l in range(1, L): A_prev = A ### START CODE HERE ### (≈ 2 lines of code) A, cache = linear_activation_forward(A_prev, parameters['W' + str(l)], parameters['b' + str(l)], "relu") caches.append(cache) # 用append()方法将cache都保存在caches列表中 ### END CODE HERE ### # Implement LINEAR -> SIGMOID. Add "cache" to the "caches" list. ### START CODE HERE ### (≈ 2 lines of code) AL, cache = linear_activation_forward(A, parameters['W' + str(L)], parameters['b' + str(L)], "sigmoid") caches.append(cache) ### END CODE HERE ### assert(AL.shape == (1,X.shape[1])) return AL, caches 测试:
X, parameters = L_model_forward_test_case()AL, caches = L_model_forward(X, parameters)print("AL = " + str(AL))print("Length of caches list = " + str(len(caches))) 结果:
keys in parameters: dict_keys(['W1', 'b1', 'W2', 'b2'])AL = [[0.17007265 0.2524272 ]]Length of caches list = 2
太好了。现在,您有了一个完整的前向传播,它接受输入X并输出一个包含您的预测的行向量 A[L]。它还将所有中间值记录在“caches”中。使用 A[L],你可以计算出你预测的成本。
5 -代价/成本函数 Cost function
现在您将实现正向和反向传播。你需要计算成本,因为你想检查你的模型是否真的在学习。
练习:使用以下公式计算交叉熵成本J:
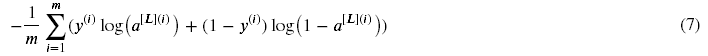
# GRADED FUNCTION: compute_costdef compute_cost(AL, Y): """ 实施等式(7)定义的代价函数/成本函数。 参数: AL - 与标签预测相对应的概率向量,维度为(1,示例数量) Y - 标签向量(例如:如果不是猫,则为0,如果是猫则为1),维度为(1,数量) 返回: cost - 交叉熵成本 """ m = Y.shape[1] # Compute loss from aL and y. ### START CODE HERE ### (≈ 1 lines of code)# cost = -np.sum(np.multiply(np.log(AL),Y) + np.multiply(np.log(1 - AL), 1 - Y)) / m cost = -np.sum((np.log(AL)*Y) + np.log(1 - AL)*(1 - Y)) / m ### END CODE HERE ### cost = np.squeeze(cost) # 保证代价的维度是我们想要的 (e.g. this turns [[17]] into 17). assert(cost.shape == ()) return cost
测试:
Y, AL = compute_cost_test_case()print("cost = " + str(compute_cost(AL, Y))) 结果:
cost = 0.414931599615397
6 -反向传播模块
就像正向传播一样,您将实现反向传播的帮助函数。请记住,反向传播用于计算损耗函数相对于参数的梯度。 提醒:
线性部分 非线性部分 线性部分 非线性部分

现在,与正向传播类似,您将分三步构建反向传播:
- LINEAR backward
- LINEAR -> ACTIVATION backward 其中 ACTIVATION 激活计算ReLU或sigmoid激活的导数
- [LINEAR -> RELU] ×× (L-1) -> LINEAR -> SIGMOID backward (整个模型)
6.1 -反向传播的线性部分
对于线性的部分的公式:



练习:使用上面的3个公式来实现linear_backward()。
# GRADED FUNCTION: linear_backwarddef linear_backward(dZ, cache): """ 为单层实现反向传播的线性部分(第L层) 参数: dZ - 相对于(当前第l层的)线性输出的成本梯度 cache - 来自当前层前向传播的值的元组(A_prev,W,b) 返回: dA_prev - 相对于激活(前一层l-1)的成本梯度,与A_prev维度相同 dW - 相对于W(当前层l)的成本梯度,与W的维度相同 db - 相对于b(当前层l)的成本梯度,与b维度相同 """ A_prev, W, b = cache m = A_prev.shape[1] ### START CODE HERE ### (≈ 3 lines of code) dW = np.dot(dZ, A_prev.T) / m db = np.sum(dZ, axis=1, keepdims=True) / m #axis=1代表对列求和 dA_prev = np.dot(W.T, dZ) ### END CODE HERE ### assert (dA_prev.shape == A_prev.shape) assert (dW.shape == W.shape) assert (db.shape == b.shape) return dA_prev, dW, db
测试:
# Set up some test inputsdZ, linear_cache = linear_backward_test_case()dA_prev, dW, db = linear_backward(dZ, linear_cache)print ("dA_prev = "+ str(dA_prev))print ("dW = " + str(dW))print ("db = " + str(db)) 结果:
dA_prev = [[ 0.51822968 -0.19517421] [-0.40506361 0.15255393] [ 2.37496825 -0.89445391]]dW = [[-0.10076895 1.40685096 1.64992505]]db = [[0.50629448]]
6.2 -反向传播的线性激活部分
接下来,您将创建一个合并两个辅助函数的函数:线性反向和激活线性反向的反向步骤。 为了帮助您实现线性激活反向,我们提供了两个反向函数:
sigmoid_backward:实现了 sigmoid() 函数的反向传播,你可以这样调用它:
dZ = sigmoid_backward(dA, activation_cache)
relu_backward: 实现了 relu() 函数的反向传播,你可以这样调用它:
dZ = relu_backward(dA, activation_cache)
如果 g(.) 是激活函数, 那么sigmoid_backward 和 relu_backward 这样计算:
![]()
练习:为LINEAR->ACTIVATION层实现反向传播。
# GRADED FUNCTION: linear_activation_backwarddef linear_activation_backward(dA, cache, activation): """ 实现LINEAR-> ACTIVATION层的后向传播。 参数: dA - 当前层l的激活后的梯度值 cache - 我们存储的用于有效计算反向传播的值的元组(值为linear_cache,activation_cache) activation - 要在此层中使用的激活函数名,字符串类型,【"sigmoid" | "relu"】 返回: dA_prev - 相对于激活(前一层l-1)的成本梯度值,与A_prev维度相同 dW - 相对于W(当前层l)的成本梯度值,与W的维度相同 db - 相对于b(当前层l)的成本梯度值,与b的维度相同 """ linear_cache, activation_cache = cache if activation == "relu": ### START CODE HERE ### (≈ 2 lines of code) dZ = relu_backward(dA, activation_cache) dA_prev, dW, db = linear_backward(dZ, linear_cache) ### END CODE HERE ### elif activation == "sigmoid": ### START CODE HERE ### (≈ 2 lines of code) dZ = sigmoid_backward(dA, activation_cache) dA_prev, dW, db = linear_backward(dZ, linear_cache) ### END CODE HERE ### return dA_prev, dW, db
测试:
AL, linear_activation_cache = linear_activation_backward_test_case()dA_prev, dW, db = linear_activation_backward(AL, linear_activation_cache, activation = "sigmoid")print ("sigmoid:")print ("dA_prev = "+ str(dA_prev))print ("dW = " + str(dW))print ("db = " + str(db) + "\n")dA_prev, dW, db = linear_activation_backward(AL, linear_activation_cache, activation = "relu")print ("relu:")print ("dA_prev = "+ str(dA_prev))print ("dW = " + str(dW))print ("db = " + str(db)) 结果:
sigmoid:dA_prev = [[ 0.11017994 0.01105339] [ 0.09466817 0.00949723] [-0.05743092 -0.00576154]]dW = [[ 0.10266786 0.09778551 -0.01968084]]db = [[-0.05729622]]relu:dA_prev = [[ 0.44090989 0. ] [ 0.37883606 0. ] [-0.2298228 0. ]]dW = [[ 0.44513824 0.37371418 -0.10478989]]db = [[-0.20837892]]
6.3-L-向后模型
现在您将为整个网络实现向后功能。回想一下,当您实现L_model_forward函数时,在每次迭代中,您都存储了一个包含(X、W、b和z)的缓存。在反向传播模块中,您将使用这些变量来计算梯度。因此,在L_model_backward函数中,您将从层L开始向后遍历所有隐藏的层。在每一步中,您将使用层L的缓存值来向后遍历层L。下面的图5显示了向后遍历。
如果对这部分知识有所遗忘的话,可以查看 2.9 逻辑回归中的梯度下降 这节的内容

在之前的前向计算中,我们存储了一些包含包含(X,W,b和z)的cache,在反向传播中,我们将会使用它们来计算梯度值,所以,在L层模型中,我们需要从L层遍历所有的隐藏层,在每一步中,我们需要使用那一层的cache值来进行反向传播。
上面我们提到了A[L],它属于输出层,A[L]=σ(Z[L]),所以我们需要计算dAL,我们可以使用下面的代码来计算它:(求导)dAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL)) # derivative of cost with respect to AL
然后,您可以使用这个激活后梯度dAL继续向后移动。如图5所示,您现在可以将dAL输入到您实现的 LINEAR->SIGMOID 向后函数中(它将使用由L_model_forward函数存储的缓存值)。之后,您必须使用for循环,使用 LINEAR->RELU 向后函数迭代所有其他层。您应该在梯度字典中存储每个dA、dW和db。为此,请使用以下公式:
![]()
例如,对于 l=3,这将把 dW[l] 存储在梯度[“dW 3”]中。
练习:为 [LINEAR->RELU] ×× (L-1) -> LINEAR -> SIGMOID 模型实施反向传播。
# GRADED FUNCTION: L_model_backwarddef L_model_backward(AL, Y, caches): """ 对[LINEAR-> RELU] *(L-1) - > LINEAR - > SIGMOID组执行反向传播,就是多层网络的向后传播 参数: AL - 概率向量,正向传播的输出(L_model_forward()) Y - 标签向量(例如:如果不是猫,则为0,如果是猫则为1),维度为(1,数量) caches - 包含以下内容的cache列表: linear_activation_forward("relu")的cache,不包含输出层 linear_activation_forward("sigmoid")的cache 返回: grads - 具有梯度值的字典 grads [“dA”+ str(l)] = ... grads [“dW”+ str(l)] = ... grads [“db”+ str(l)] = ... """ grads = {} L = len(caches) # the number of layers m = AL.shape[1] Y = Y.reshape(AL.shape) # after this line, Y is the same shape as AL # 初始化反向传播 ### START CODE HERE ### (1 line of code) dAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL)) ### END CODE HERE ### # 第L层 (SIGMOID -> LINEAR) gradients. Inputs: "AL, Y, caches". Outputs: "grads["dAL"], grads["dWL"], grads["dbL"] ### START CODE HERE ### (approx. 2 lines) current_cache = caches[L-1] # 因为索引是从0开始的 grads["dA" + str(L)], grads["dW" + str(L)], grads["db" + str(L)] = linear_activation_backward(dAL, current_cache, "sigmoid") ### END CODE HERE ### for l in reversed(range(L - 1)): # 第1层: (RELU -> LINEAR) gradients. # Inputs: "grads["dA" + str(l + 2)], caches". Outputs: "grads["dA" + str(l + 1)] , grads["dW" + str(l + 1)] , grads["db" + str(l + 1)] ### START CODE HERE ### (approx. 5 lines) current_cache = caches[l] grads["dA" + str(l + 1)] , grads["dW" + str(l + 1)] , grads["db" + str(l + 1)] = linear_activation_backward(grads["dA" + str(l + 2)], current_cache, "relu") ### END CODE HERE ### return grads 测试:
AL, Y_assess, caches = L_model_backward_test_case()grads = L_model_backward(AL, Y_assess, caches)print ("dW1 = "+ str(grads["dW1"]))print ("db1 = "+ str(grads["db1"]))print ("dA1 = "+ str(grads["dA1"])) 结果:
dW1 = [[0.41010002 0.07807203 0.13798444 0.10502167] [0. 0. 0. 0. ] [0.05283652 0.01005865 0.01777766 0.0135308 ]]db1 = [[-0.22007063] [ 0. ] [-0.02835349]]dA1 = [[ 0. 0.52257901] [ 0. -0.3269206 ] [ 0. -0.32070404] [ 0. -0.74079187]]
6.4 -更新参数
在本节中,您将使用梯度下降更新模型参数:

其中α是学习率。计算更新后的参数后,将其存储在参数字典中。
练习:实现update_parameters()使用梯度下降来更新参数。
说明:使用梯度下降在每个 W[L] 和 b[L] 更新参数 l=1,2,...,L
# GRADED FUNCTION: update_parametersdef update_parameters(parameters, grads, learning_rate): """ 使用梯度下降更新参数 参数: parameters - 包含你的参数的字典 grads - 包含梯度值的字典,是L_model_backward的输出 返回: parameters - 包含更新参数的字典 参数[“W”+ str(l)] = ... 参数[“b”+ str(l)] = ... """ L = len(parameters) // 2 # 神经网络的层数 # 用一个for循环为每一个参数更新规则 ### START CODE HERE ### (≈ 3 lines of code) for l in range(L): # 梯度下降法 parameters["W" + str(l+1)] = parameters["W" + str(l + 1)] - learning_rate * grads["dW" + str(l + 1)] parameters["b" + str(l+1)] = parameters["b" + str(l + 1)] - learning_rate * grads["db" + str(l + 1)] ### END CODE HERE ### return parameters
测试:
parameters, grads = update_parameters_test_case()parameters = update_parameters(parameters, grads, 0.1)print ("W1 = "+ str(parameters["W1"]))print ("b1 = "+ str(parameters["b1"]))print ("W2 = "+ str(parameters["W2"]))print ("b2 = "+ str(parameters["b2"])) 结果:
W1 = [[-0.59562069 -0.09991781 -2.14584584 1.82662008] [-1.76569676 -0.80627147 0.51115557 -1.18258802] [-1.0535704 -0.86128581 0.68284052 2.20374577]]b1 = [[-0.04659241] [-1.28888275] [ 0.53405496]]W2 = [[-0.55569196 0.0354055 1.32964895]]b2 = [[-0.84610769]]
7 -结论
恭喜你实现了构建深层神经网络所需的所有功能! 我们知道这是一项漫长的任务,但今后只会变得更好。作业的下一部分更容易。 在下一个作业中,您将把所有这些放在一起构建两个模型:
- 一个两层的神经网络
- 一个L层的神经网络
事实上,您将使用这些模型来对猫和非猫图像进行分类!
转载地址:http://opuvi.baihongyu.com/